The Real Cost of AI Visibility Tracking: What 7,300+ Checks Across 12 Brands Taught Us

We analyzed 7,300+ visibility checks across 12 brands to find the optimal way to track brand mentions in AI responses. The results challenge conventional assumptions about accuracy, cost, and measurement strategy.
More and more people are using AI assistants like ChatGPT, Claude, and Perplexity to find products, compare options, and make buying decisions. If your brand shows up in those AI-generated answers, you win attention. If it doesn't, you're invisible — no matter how good your SEO is.
But tracking whether AI actually mentions your brand is expensive. Every check requires calling an AI engine, waiting for a response, and then analyzing what came back. Do that across hundreds of search queries, multiple AI engines, and several rounds for consistency — and the bills add up quickly.
We analyzed 7,300+ visibility checks across 12 brands in industries from crypto to fintech to retail to answer three practical questions:
- Can you use a cheaper AI model to save money?
- How many times do you need to check each query?
- Is it better to check more queries or repeat the same queries more often?
The answers changed how we build our product. Here's what we learned.
How AI Visibility Tracking Works (And Where the Money Goes)
Here's the basic process. Each visibility check has two steps:
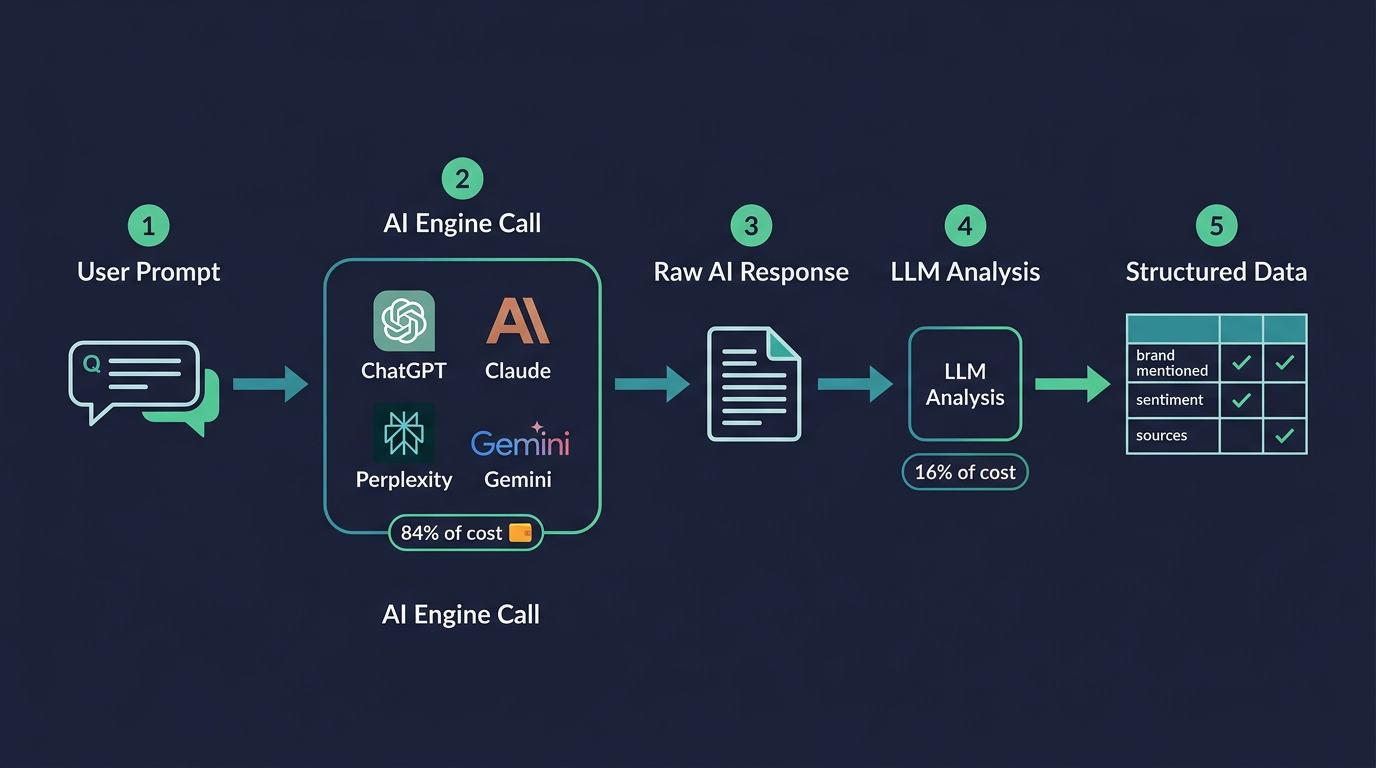
Step 1 — Ask the AI engine (84% of cost). You send a real question to an AI engine — something a customer might actually ask, like "what's the best loyalty program software?" The engine searches the web, reads relevant pages, and writes an answer. This step is expensive because it involves real-time web search and a long, detailed response.
Step 2 — Analyze the answer (16% of cost). A second AI call reads the engine's response and extracts structured data: Was the brand mentioned? Was it recommended, just acknowledged, or compared to competitors? What was the sentiment? Which sources were cited? This step is much cheaper since it's just reading and classifying text.
We measured the exact costs across 100 queries for a real brand tracking project:
| Step | What It Does | Cost per Check |
|---|---|---|
| Engine call | Ask AI + web search | $0.020 |
| Analysis call | Classify the response | $0.004 |
| Total | $0.023 |
A single check costs about 2.3 cents. That sounds small, but at scale it compounds. Checking 100 queries across 4 AI engines with 5 rounds each means 2,000 API calls — about $47 per check cycle. Run that monthly and you're at $187/month just on API costs.
The engine call dominates at 84% of the total. Any savings strategy needs to focus there.
Can You Use a Cheaper Model to Save Money?
This was our first question. ChatGPT's flagship model (GPT-5.2) is powerful but expensive. OpenAI also offers GPT-5-mini — a smaller, cheaper model built on the same architecture. Could we use the mini model for our visibility checks and get similar enough results at a fraction of the cost?
To test this, we ran 100 real queries from a production loyalty & promotions brand through both models. GPT-5.2 had 564 existing checks in our database; we ran 1,000 fresh checks with GPT-5-mini.
What We Found
| What We Measured | GPT-5.2 | GPT-5-mini |
|---|---|---|
| Brand mention rate | 7.4% | 4.3% |
| Consistency across runs | 95% | 96% |
| Avg sources cited | 0.8 | 3.0 |
| Avg response length | 3,310 chars | 5,842 chars |
The mention rates were noticeably different: 7.4% vs. 4.3%. More importantly, the models cited completely different sources. GPT-5.2 cited the brand's own website 22 times across its checks. GPT-5-mini cited it zero times. They weren't just giving slightly different numbers — they were finding and referencing entirely different web pages.
Why This Matters
The cheaper model uses a different web search strategy, retrieves different sources, and makes different decisions about what to include in its answers. Even though it's built on the same architecture, it produces meaningfully different visibility data.
This is a critical point: you need to track with the model your audience actually uses. All ChatGPT tiers — Free, Go, Plus, and Pro — run GPT-5.2. Nobody interacts with GPT-5-mini as a consumer. Using it for visibility tracking doesn't give you a "close enough" approximation — it gives you data about a model nobody talks to.
The bottom line: there's no shortcut on the engine call. You have to use the real model, and that means the cost per check is fixed. The savings have to come from being smarter about how many checks you run and which queries you track.
How Many Times Do You Need to Check Each Query?
AI responses aren't consistent. Ask ChatGPT the same question twice and you might get different answers — different sources, different brands mentioned, different wording. AI models are inherently non-deterministic — even with the same input, they can produce different outputs. On top of that, each call performs a fresh web search, and the web itself changes constantly. Both factors compound to make every response unique.
To deal with this randomness, you can check the same query multiple times (called "runs") and average the results. But each additional run costs money. So: how many runs do you actually need?
We analyzed this using our production data, measuring how accuracy improves as you add more runs per query:
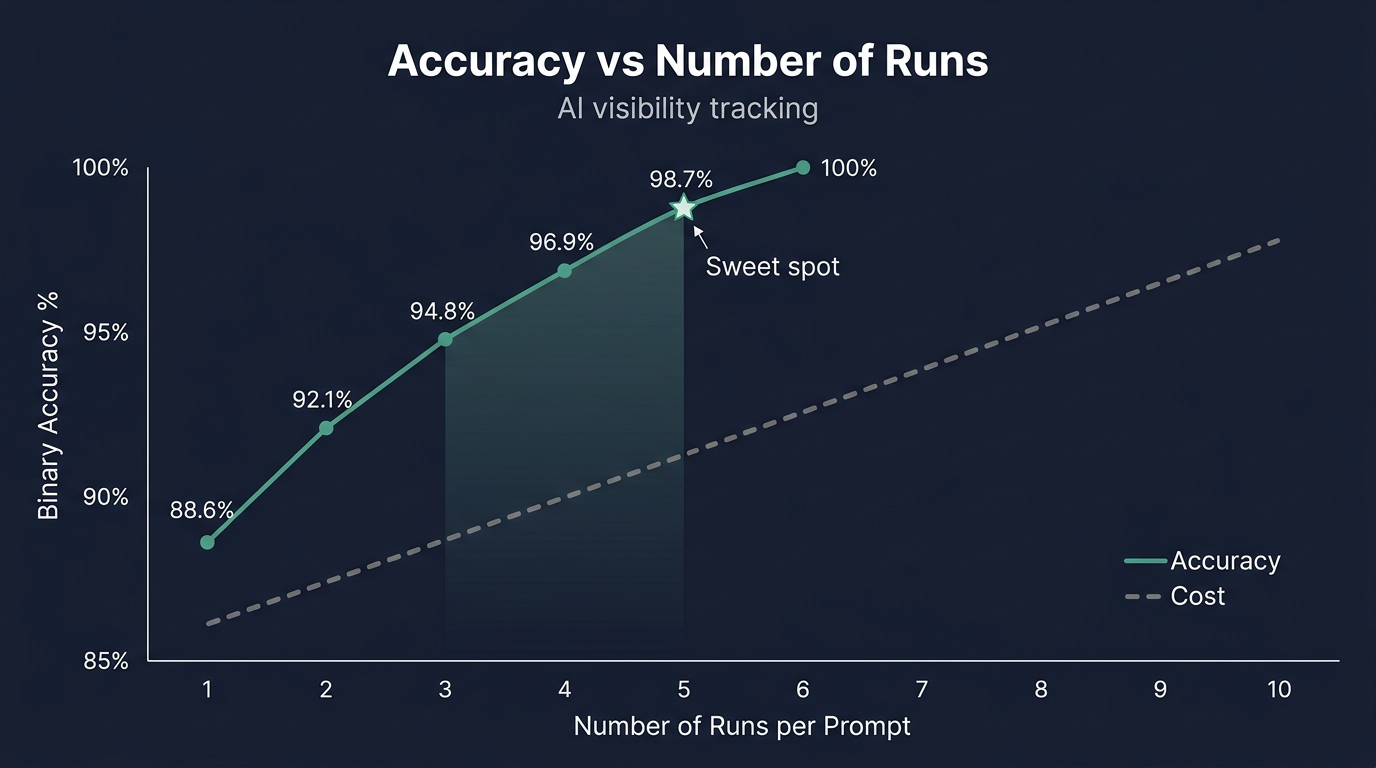
| Runs per Query | Accuracy | Queries Misclassified (out of 100) | Cost Savings vs 10 Runs |
|---|---|---|---|
| 1 | 88.6% | ~7 queries wrong | 90% cheaper |
| 2 | 92.1% | ~5 queries wrong | 80% cheaper |
| 3 | 94.8% | ~3 queries wrong | 70% cheaper |
| 4 | 96.9% | ~2 queries wrong | 60% cheaper |
| 5 | 98.7% | less than 1 wrong | 50% cheaper |
| 6+ | ~100% | ~0 wrong | baseline |
Here's how to read this: "accuracy" means whether a given number of runs correctly identifies a query as "brand mentioned" or "brand not mentioned," compared to the answer you'd get with 10 runs. At 5 runs, fewer than 1 query out of 100 gets misclassified.
The sweet spot is 5 runs. Going from 1 to 5 runs cuts misclassifications from 7 queries down to less than 1. Going from 5 to 10 runs barely improves accuracy but doubles your cost.
Individual Queries Are Hard to Pin Down
Here's an uncomfortable reality. Even with multiple runs, you can't be very precise about individual query mention rates. To illustrate: if you run a query 10 times and see the brand mentioned once, what's the true mention rate? Statistically, it could be anywhere from 2% to 40%. That's a huge range.
Think of it like flipping a weighted coin. If you flip it 10 times and get 1 heads, you know the coin isn't fair — but you can't tell if it lands heads 5% of the time or 35% of the time. You'd need 50–100 flips to narrow that down, and at $0.023 per flip, that's not economical.
What this means in practice: Don't obsess over individual query scores. A query showing "mentioned 1 out of 5 times" is a signal worth tracking, but it's not a precise measurement. The real value comes from looking at the big picture — mention rates across all your queries.
The Counterintuitive Finding: Track More Queries, Not More Runs
This is the most important finding from our analysis, and it goes against most people's instincts.
Think of it this way. Imagine you're inside a building with no doors, and you want to know what the landscape outside looks like. Your only option is to cut windows into the walls. Each query you track is like a window — a small opening that gives you a glimpse of the world outside.
You have a limited budget for window-making. You could spend it two ways:
- A few large, crystal-clear windows — polishing each one until the glass is spotless. You get a sharp view in three directions, but the rest of the landscape is a complete blind spot.
- Many smaller windows with slightly foggy glass — scattered across every wall, each one facing a different direction. No single view is perfect, but together they give you a panoramic picture of what's actually out there.

That's exactly how AI visibility measurement works. Each query is a window into how AI talks about your industry. "Best CRM for small business" shows you one view. "How do I manage customer relationships?" shows you another. "Enterprise sales pipeline tools" shows you a third. They're all looking at different parts of the same landscape — your brand's visibility across AI.
Polishing each window (running the same query 10 times) makes that one view sharper. But cutting more windows (tracking more queries with fewer runs each) reveals parts of the landscape you'd otherwise miss entirely. Even with slightly foggy glass, twelve windows facing every direction will always tell you more about the outside world than three perfect windows all facing the same way.
Now let's put real numbers on this. Imagine you have a budget for 60 API calls. You can spend it two ways:
- Option A ("go deep"): Track 20 queries, check each one 3 times
- Option B ("go wide"): Track 60 queries, check each one once
Most people's gut says Option A is better — you get more reliable data per query. But the math says otherwise.
Why "Go Wide" Wins
When you track your brand's overall AI visibility — the percentage of queries where AI mentions you — the precision of that number depends on two things:
- How well your queries represent the full landscape — Your 20 or 60 tracked queries are a sample of the thousands of questions your audience could ask AI. Some of those queries will mention your brand, most won't — and that's not an error, it's reality. But if your sample happens to miss the queries where you do get mentioned (or over-represents them), your overall visibility number will be off. The more diverse queries you track, the more representative your sample becomes.
- Run-to-run randomness — Whether any single run of the same query happens to catch a mention. This is the noise you reduce by running the same query multiple times.
We measured both sources of uncertainty across our 12 brands. Across every industry we tested, the variation between different queries was 1.4x to 47x larger than the run-to-run noise on any single query. In other words, the biggest risk to your aggregate visibility number isn't that a single run misses a mention — it's that your sample of queries doesn't capture enough of the query landscape.
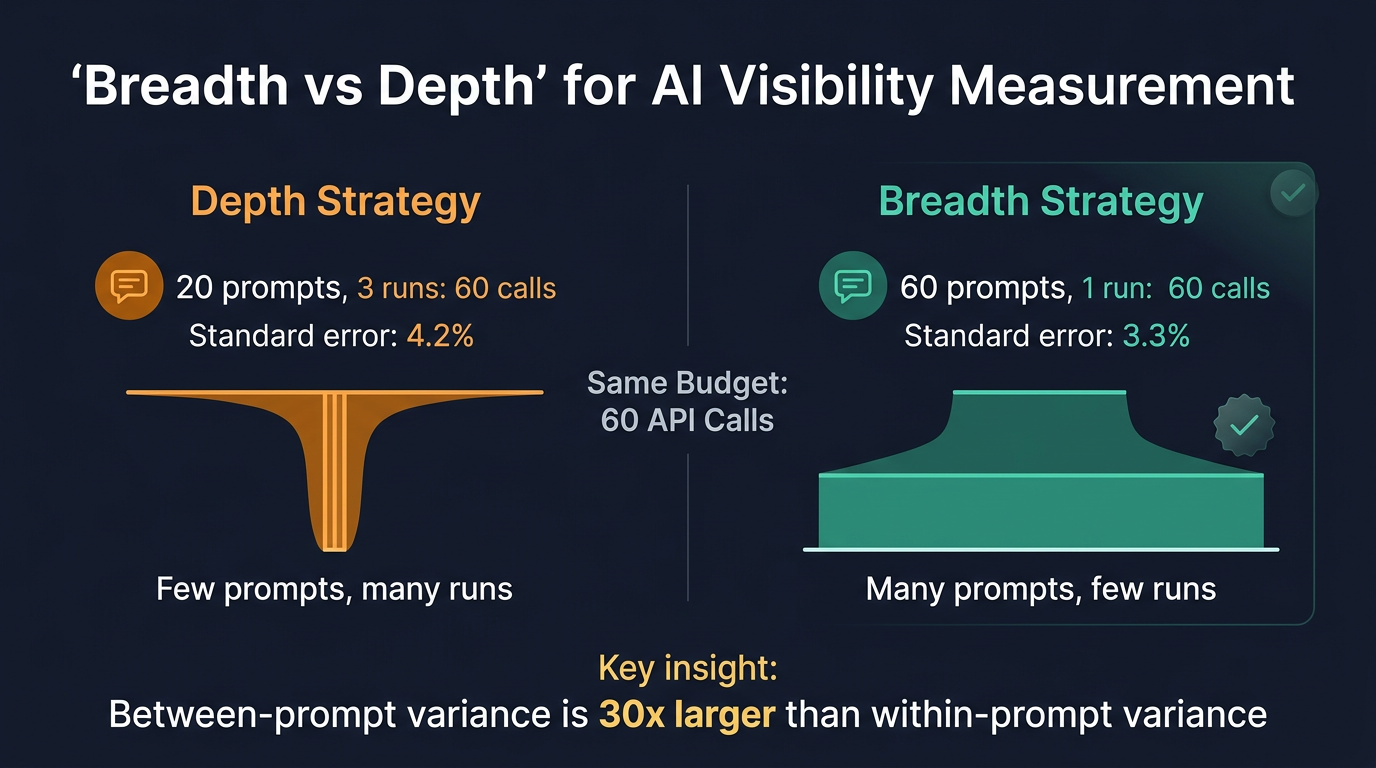
With the same budget of 60 API calls:
| Strategy | Queries | Runs Each | Estimation Error | Coverage |
|---|---|---|---|---|
| Go deep | 20 | 3 | 4.2% | 20 queries |
| Go wide | 60 | 1 | 3.3% | 60 queries |
The "go wide" approach isn't just broader — it's actually more accurate at estimating your overall visibility, because it reduces the much larger source of uncertainty — how well your tracked queries represent the full query landscape.
Put simply: 60 slightly noisy measurements of different queries give you a better picture than 20 precise measurements of the same queries — just like our building with twelve foggy windows tells you more about the landscape than three spotless ones facing the same direction.
This Holds Across Every Industry
We didn't just test this on one brand. We ran the analysis across all 12 brands in our production database, spanning mention rates from 0% to 38%:
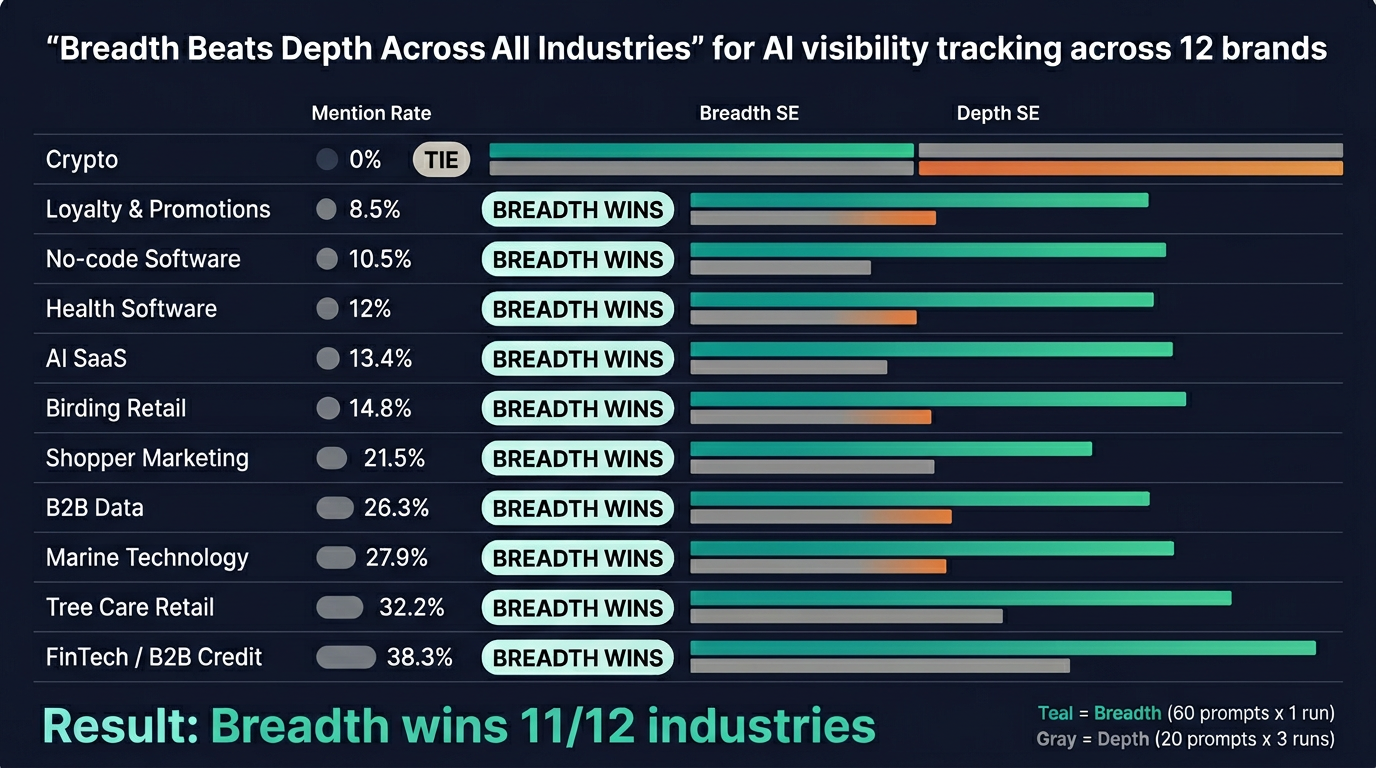
| Industry | Mention Rate | Query Variation vs. Run Noise | Go Wide Wins? |
|---|---|---|---|
| Crypto | 0% | — | Tie |
| Loyalty & Promotions | 8.5% | 3.4x larger | Yes |
| No-code Software | 10.5% | Very large | Yes |
| Health Software | 12% | 20.9x larger | Yes |
| AI SaaS | 13.4% | 20.4x larger | Yes |
| Birding Retail | 14.8% | 4.6x larger | Yes |
| Shopper Marketing | 21.5% | 1.4x larger | Yes |
| B2B Data | 26.3% | 41x larger | Yes |
| Marine Technology | 27.9% | 11x larger | Yes |
| Tree Care Retail | 32.2% | 47.3x larger | Yes |
| FinTech / B2B Credit | 38.3% | 12.1x larger | Yes |
"Go wide" wins for 11 out of 12 industries. The only tie was a crypto brand with 0% mentions (nothing to detect either way). Whether your brand is mentioned 8% or 38% of the time, tracking more queries always beats running the same queries more often.
This isn't a quirk of one dataset. It's a fundamental property of how AI visibility works. Different queries tap into different topics, different sources, and different parts of the AI's training data. That natural variation across the query landscape is always much larger than the randomness you get from running the same query twice.
The key requirement is that your queries need to be genuinely diverse. "Best loyalty software" and "top loyalty platform" are basically the same question — adding the second doesn't tell you much new. But "best loyalty software" and "how to reduce customer churn" are different queries that reveal different aspects of your visibility.
What This Actually Costs
Here's a concrete cost breakdown based on our measured token usage:
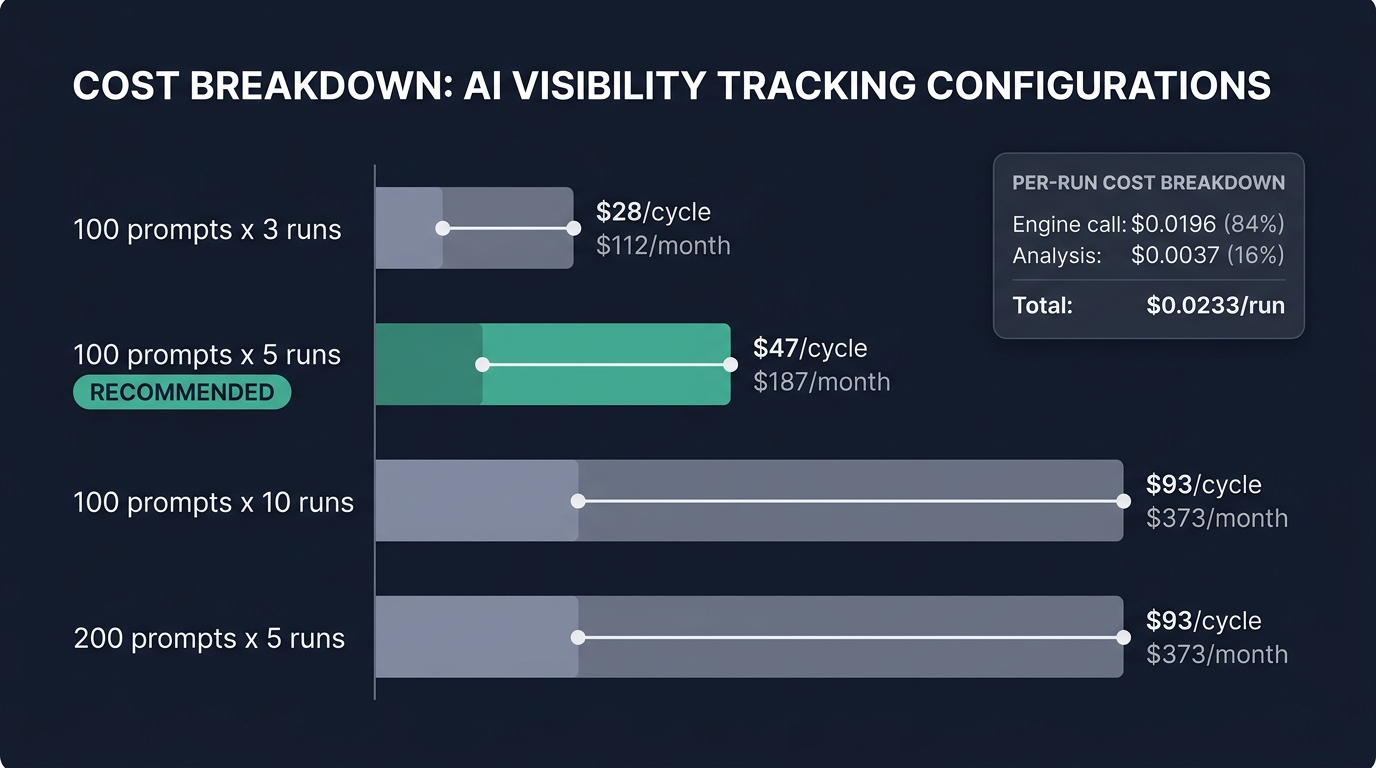
| Configuration | API Calls | Cost per Cycle | Monthly (4 cycles) |
|---|---|---|---|
| 100 queries x 3 runs | 1,200 | $28 | $112 |
| 100 queries x 5 runs | 2,000 | $47 | $187 |
| 100 queries x 10 runs | 4,000 | $93 | $373 |
| 200 queries x 5 runs | 4,000 | $93 | $373 |
Notice the last two rows: 100 queries with 10 runs costs the same as 200 queries with 5 runs. Based on everything we've learned, the 200-query option is strictly better — you get double the coverage with only slightly less per-query precision.
The sweet spot for most brands is 100–200 diverse queries, 5 runs each, checked monthly. That gives you 98.7% accuracy at $47–$93 per cycle.
What We Recommend
Based on 7,300+ visibility checks across 12 brands, here's our practical advice:
1. Use the same AI model your audience uses. For ChatGPT, that's GPT-5.2 — the model behind Free, Go, Plus, and Pro tiers. Cheaper API models produce different results and different source citations. They don't save you money; they give you wrong data.
2. Five runs per query is the sweet spot. It catches 98.7% of mentions correctly. Going beyond 5 runs doubles your cost for minimal improvement.
3. Track more queries rather than running the same ones more often. With a fixed budget, broader coverage always produces a more accurate overall picture. The difference between queries matters far more than run-to-run randomness.
4. Don't over-interpret individual query scores. A query showing "mentioned 1 out of 5 times" is directional, not precise. Make decisions based on aggregate patterns across all your queries and categories.
5. Let time work for you. Running regular check cycles catches trends that any single cycle might miss. A query where your brand appears 17% of the time will show up within 2–3 monthly cycles with high confidence.
You Don't Have to Build This Yourself
If the statistics, API orchestration, and cost optimization in this article feel complex — they are. Getting AI visibility tracking right involves query discovery, multi-engine API management, statistical analysis, cost control, and ongoing monitoring. It's a full engineering problem on top of the GEO strategy itself.
That's exactly what Ripenn handles. We manage the entire pipeline — from discovering which queries matter for your brand, to running optimized check cycles across ChatGPT, Claude, Perplexity, and Gemini, to surfacing actionable insights on where your visibility is growing or slipping. All the statistical nuances in this article (the right number of runs, breadth vs. depth, per-query confidence) are built into how we measure, so you can focus on the strategy and content that actually improves your visibility.
If you want to see where your brand stands in AI search results today, try Ripenn — no API keys or engineering work required.